

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
§データベース・エボリューション
リレーショナル・データベースを使う場合、スキーマ・エボリューションを追跡・整理する方法が必要になります。特に、次のような場合には、データベース・スキーマへの変更を追跡するために高度なツールを利用したくなると思います。
- チームで開発を行なっていて、各メンバーがスキーマへのすべての変更を知っておく必要がある
- アプリケーションを本番サーバにデプロイするにあたって、データベース・スキーマを安全にアップグレードしたい
- 複数台のマシンで開発を行なっていて、全マシンでデータベース・スキーマを同期させたい
§エボリューション・スクリプト
Play はエボリューション・スクリプトによってデータベース・エボリューションを追跡します。このスクリプトはただの SQL で記述し、アプリケーションの conf/evolutions/{データベース名} というディレクトリに保存することになっています。デフォルト・データベースにエボリューションを適用したい場合は、スクリプトの保存先は、 conf/evolutions/default になります。
最初のスクリプトは 1.sql、2番目のスクリプトは 2.sql、…というように名前をつけます。
各スクリプトはそれぞれ二つのパートで構成されています。
- Ups パートは、必要なスキーマの変換方法の記述
- Downs パートは、上記の変換をもとに戻す方法の記述
試しに、基本的なアプリケーションを始めるための最初のエボリューション・スクリプトを作成してみましょう。
# Users スキーマ
# --- !Ups
CREATE TABLE User (
id bigint(20) NOT NULL AUTO_INCREMENT,
email varchar(255) NOT NULL,
password varchar(255) NOT NULL,
fullname varchar(255) NOT NULL,
isAdmin boolean NOT NULL,
PRIMARY KEY (id)
);
# --- !Downs
DROP TABLE User;
ご覧のとおり、Ups パートと Downs パートはコメントで区切る必要があります。
Play は
.sqlファイルをセミコロンで区切ってから、それらをひとつひとつデータベースに対して実行します。そのため、文の中でセミコロンを使用する必要がある場合は;の代わりに;;を入力する事でエスケープします。例えばINSERT INTO punctuation(name, character) VALUES ('semicolon', ';;');となります。
データベースが application.conf で設定されていて、エボリューション・スクリプトが存在する場合は、エボリューションが自動的に有効化されます。エボリューションを無効化したい場合は、 evolutionplugin=disabled という設定を行なってください。例えば、自前でデータベースをセットアップするような自動化テストを書くような場合は、テスト環境においてエボリューションを無効化する設定を行いましょう。
エボリューションが有効化されていると、Play は開発モードの場合リクエスト毎に、本番モードの場合アプリケーションの起動前にスキーマの状態をチェックします。開発モードでは、データベース・スキーマが最新でない場合、適切な SQL スクリプトを実行してデータベース・スキーマを同期させるように促すエラーページが表示されます。
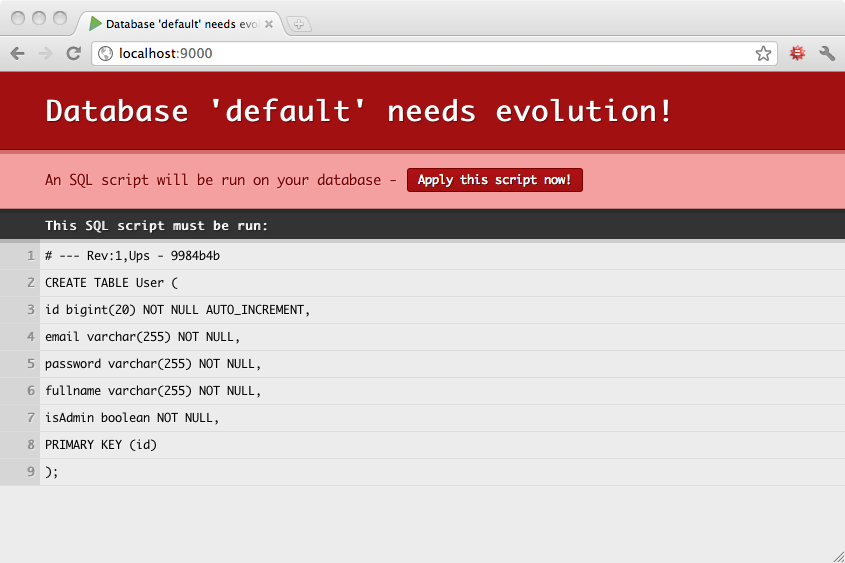
SQL スクリプトの内容に問題がなければ、この Apply evolutions ボタンをクリックすることで即座にスクリプトを実行することができます。
§同時に行われた変更を同期させる
仮に、プロジェクトに二人の開発者がいるとします。開発者 A は新しいテーブルを必要とする新機能を担当しています。そこで、開発者 A は次のような 2.sql を作成します。
# Post 追加
# --- !Ups
CREATE TABLE Post (
id bigint(20) NOT NULL AUTO_INCREMENT,
title varchar(255) NOT NULL,
content text NOT NULL,
postedAt date NOT NULL,
author_id bigint(20) NOT NULL,
FOREIGN KEY (author_id) REFERENCES User(id),
PRIMARY KEY (id)
);
# --- !Downs
DROP TABLE Post;
Play はこのエボリューション・スクリプトを開発者 A のデータベースで実行します。
一方、開発者 B は User テーブルのスキーマ変更を要する新機能を担当しています。そこで、開発者 B は次のような 2.sql を作成します。
# User 変更
# --- !Ups
ALTER TABLE User ADD age INT;
# --- !Downs
ALTER TABLE User DROP age;
開発者 B は担当している機能を実装し終わったあと、それをコミットします (彼らが Git を使っていることにしましょう)。すると、開発者 A は作業を続行するにあたって、チームメイトが行った作業をマージする必要があります。彼は git pull を実行しますが、マージにはコンフリクトがあります。
Auto-merging db/evolutions/2.sql
CONFLICT (add/add): Merge conflict in db/evolutions/2.sql
Automatic merge failed; fix conflicts and then commit the result.
二人の開発者がそれぞれ 2.sql を作成したため、開発者 A はこのファイルの内容をマージしなければなりません。
<<<<<<< HEAD
# Post 追加
# --- !Ups
CREATE TABLE Post (
id bigint(20) NOT NULL AUTO_INCREMENT,
title varchar(255) NOT NULL,
content text NOT NULL,
postedAt date NOT NULL,
author_id bigint(20) NOT NULL,
FOREIGN KEY (author_id) REFERENCES User(id),
PRIMARY KEY (id)
);
# --- !Downs
DROP TABLE Post;
=======
# User 変更
# --- !Ups
ALTER TABLE User ADD age INT;
# --- !Downs
ALTER TABLE User DROP age;
>>>>>>> devB
このマージは簡単ですね。
# Post 追加と User 変更
# --- !Ups
ALTER TABLE User ADD age INT;
CREATE TABLE Post (
id bigint(20) NOT NULL AUTO_INCREMENT,
title varchar(255) NOT NULL,
content text NOT NULL,
postedAt date NOT NULL,
author_id bigint(20) NOT NULL,
FOREIGN KEY (author_id) REFERENCES User(id),
PRIMARY KEY (id)
);
# --- !Downs
ALTER TABLE User DROP age;
DROP TABLE Post;
このエボリューション・スクリプトが表すデータベースのリビジョン 2 は、最初に開発者 A が適用したリビジョン 2 とは内容が異なります。
このとき、 Play はこの二つのリビジョンの内容の違いを検出して、まずは現在適用されている古い方のリビジョン 2 への変更を取り消し、それから新しい方のリビジョン 2 のスクリプトを適用します。
§不整合状態
たまにエボリューション・スクリプトに間違いがあって、適用に失敗してしまうこともあるでしょう。その場合、 Play はデータベース・スキーマを不整合状態としてマークします。そして、続行する前に問題を手動で解決するようにあなたに促します。
例として、Ups スクリプトにエラーを含む次のようなエボリューションを作成してみましょう。
# User にカラムを追加
# --- !Ups
ALTER TABLE Userxxx ADD company varchar(255);
# --- !Downs
ALTER TABLE User DROP company;
このエボリューションの適用は失敗し、 Play はデータベース・スキーマを不整合状態としてマークします。
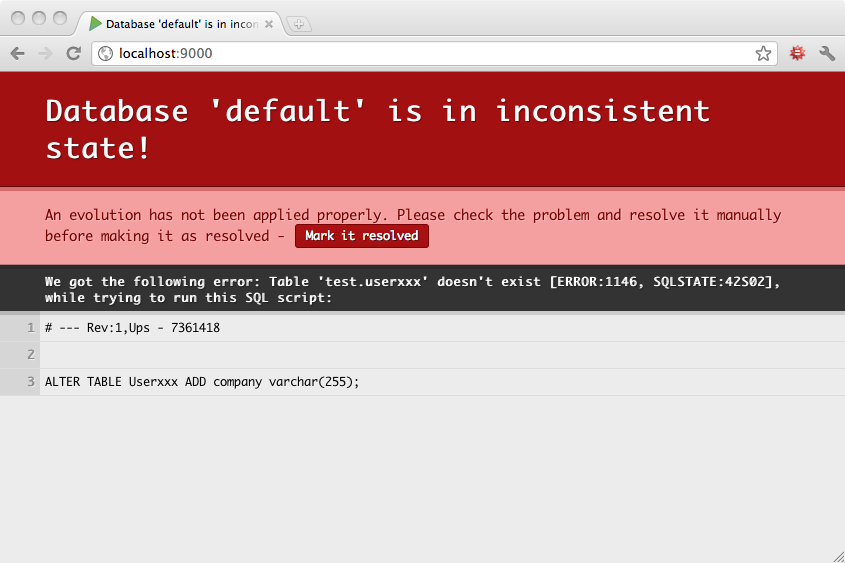
続行するためには、まずこの不整合を解決する必要があります。今回は、正しい SQL コマンドを実行します。
ALTER TABLE User ADD company varchar(255);
次に、ボタンをクリックして、不整合を手動で解決したことを Play に知らせます。
しかし、エボリューション・スクリプトはまだ間違ったままなので、修正したいところです。そこで、以下のように 3.sql を編集します。
# User にカラムを追加
# --- !Ups
ALTER TABLE User ADD company varchar(255);
# --- !Downs
ALTER TABLE User DROP company;
Play はこの新しいエボリューションを検知して、以前のリビジョン 3 と置き換え、適切なスクリプトを実行します。これで、全ての間違いが修正されて、本来の作業に戻ることができます。
ただし、開発モードでは単に開発用のデータベースを破棄して、全てのエボリューションを最初から適用しなおす方が簡単なことも多々あります。
§エボリューションのストレージと制限
エボリューションはデータベースの PLAY_EVOLUTIONS というテーブルに保存されます。 text 型のカラムに実際のエボリューション・スクリプトが保存されています。データベースによっては 64kb のサイズ制限が text 型のカラムに付くことがあります。64kb の制限に対処する場合 — 手動でカラムの型を変えることで play_evolutions のテーブル構造を変更するか、(より好ましい方法として) 64kb よりも小さいサイズの複数のスクリプトに分割することができます。
§本番でエボリューションを実行する
dev モードでは play コンソールで ‘Apply Evolutions’ をクリックする事で適切な up と down スクリプトが実行されます。 PROD モードでエボリューションを使用する場合は、考慮しなければならない事が2つあります。
UP エボリューションを自動で適用したい場合、 -DapplyEvolutions.<database>=true をシステムプロパティに設定するか、 applyEvolutions.<database>=true を application.conf に設定します。
もし Play によって算出されたエボリューション・スクリプトが UP エボリューションしか含んでいなく、このプロパティがセットされていた場合 Play はこれらを適用してサーバーを起動します。
UP と DOWN エボリューションを自動で実行したい場合 -DapplyDownEvolutions.<database>=true システムプロパティを設定します。この設定を application.conf に持つ事は推奨されません。
もし Play によって算出されたエボリューション・スクリプトが DOWN エボリューションしか持っていなく、このプロパティが設定されていない場合 Play はこれを実行せず、サーバーも起動しません。
§エボリューションと Postgres もしくは Oracle を使用している複数ホスト
アプリケーションが複数ホストで動作している場合は evolutions.use.locks=true プロパティを設定します。このプロパティが設定されている場合、データベースロックを使って一つのホストがエボリューションを適用する事を保証します。Play はロックを実行するために SELECT FOR UPDATE NOWAIT に使われる PLAY_EVOLUTIONS_LOCKS というテーブルを作成します。
§エボリューションと Postgres もしくは Oracle を使用していない複数ホスト
アプリケーションが複数ホストで動作している場合は、エボリューションはオフにするべきです。複数ホストがエボリューション・スクリプトを同時に実行しようとする可能性があり、片方が失敗しデータベースが不整合の状態のままになってしまう危険を伴います。
このドキュメントの翻訳は Play チームによってメンテナンスされているものではありません。 間違いを見つけた場合、このページのソースコードを ここ で確認することができます。 ドキュメントガイドライン を読んで、お気軽にプルリクエストを送ってください。