

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
§Managing database evolutions
When you use a relational database, you need a way to track and organize your database schema evolutions. Typically there are several situations where you need a more sophisticated way to track your database schema changes:
- When you work within a team of developers, each person needs to know about any schema change.
- When you deploy on a production server, you need to have a robust way to upgrade your database schema.
- If you work on several machines, you need to keep all database schemas synchronized.
§Enable evolutions
Add evolutions into your dependencies list. For example, in build.sbt:
libraryDependencies += evolutions
§Evolutions scripts
Play tracks your database evolutions using several evolutions script. These scripts are written in plain old SQL and should be located in the conf/evolutions/{database name} directory of your application. If the evolutions apply to your default database, this path is conf/evolutions/default.
The first script is named 1.sql, the second script 2.sql, and so on…
Each script contains two parts:
- The Ups part the describe the required transformations.
- The Downs part that describe how to revert them.
For example, take a look at this first evolution script that bootstrap a basic application:
# Users schema
# --- !Ups
CREATE TABLE User (
id bigint(20) NOT NULL AUTO_INCREMENT,
email varchar(255) NOT NULL,
password varchar(255) NOT NULL,
fullname varchar(255) NOT NULL,
isAdmin boolean NOT NULL,
PRIMARY KEY (id)
);
# --- !Downs
DROP TABLE User;
As you see you have to delimit the both Ups and Downs section by using comments in your SQL script.
Play splits your
.sqlfiles into a series of semicolon-delimited statements before executing them one-by-one against the database. So if you need to use a semicolon within a statement, escape it by entering;;instead of;. For example,INSERT INTO punctuation(name, character) VALUES ('semicolon', ';;');.
Evolutions are automatically activated if a database is configured in application.conf and evolution scripts are present. You can disable them by setting play.evolutions.enabled=false. For example when tests set up their own database you can disable evolutions for the test environment.
When evolutions are activated, Play will check your database schema state before each request in DEV mode, or before starting the application in PROD mode. In DEV mode, if your database schema is not up to date, an error page will suggest that you synchronise your database schema by running the appropriate SQL script.
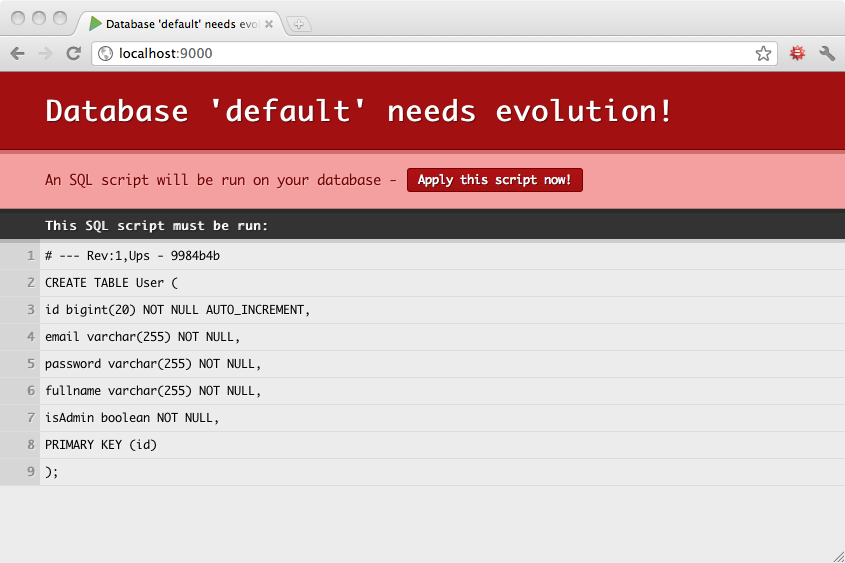
If you agree with the SQL script, you can apply it directly by clicking on the ‘Apply evolutions’ button.
§Evolutions configuration
Evolutions can be configured both globally and per datasource. For global configuration, keys should be prefixed with play.evolutions. For per datasource configuration, keys should be prefixed with play.evolutions.db.<datasourcename>, for example play.evolutions.db.default. The following configuration options are supported:
enabled- Whether evolutions are enabled. If configured globally to be false, it disables the evolutions module altogether. Defaults to true.autocommit- Whether autocommit should be used. If false, evolutions will be applied in a single transaction. Defaults to true.useLocks- Whether a locks table should be used. This must be used if you have many Play nodes that may potentially run evolutions, but you want to ensure that only one does. It will create a table calledplay_evolutions_lock, and use aSELECT FOR UPDATE NOWAITorSELECT FOR UPDATEto lock it. This will only work for Postgres, Oracle, and MySQL InnoDB. It will not work for other databases. Defaults to false.autoApply- Whether evolutions should be automatically applied. In dev mode, this will cause both ups and downs evolutions to be automatically applied. In prod mode, it will cause only ups evolutions to be automatically applied. Defaults to false.autoApplyDowns- Whether down evolutions should be automatically applied. In prod mode, this will cause down evolutions to be automatically applied. Has no effect in dev mode. Defaults to false.
For example, to enable autoApply for all evolutions, you might set play.evolutions.autoApply=true in application.conf or in a system property. To disable autocommit for a datasource named default, you set play.evolutions.db.default.autocommit=false.
§Synchronizing concurrent changes
Now let’s imagine that we have two developers working on this project. Developer A will work on a feature that requires a new database table. So he will create the following 2.sql evolution script:
# Add Post
# --- !Ups
CREATE TABLE Post (
id bigint(20) NOT NULL AUTO_INCREMENT,
title varchar(255) NOT NULL,
content text NOT NULL,
postedAt date NOT NULL,
author_id bigint(20) NOT NULL,
FOREIGN KEY (author_id) REFERENCES User(id),
PRIMARY KEY (id)
);
# --- !Downs
DROP TABLE Post;
Play will apply this evolution script to Developer A’s database.
On the other hand, developer B will work on a feature that requires altering the User table. So he will also create the following 2.sql evolution script:
# Update User
# --- !Ups
ALTER TABLE User ADD age INT;
# --- !Downs
ALTER TABLE User DROP age;
Developer B finishes his feature and commits (let’s say they are using Git). Now developer A has to merge the his colleague’s work before continuing, so he runs git pull, and the merge has a conflict, like:
Auto-merging db/evolutions/2.sql
CONFLICT (add/add): Merge conflict in db/evolutions/2.sql
Automatic merge failed; fix conflicts and then commit the result.
Each developer has created a 2.sql evolution script. So developer A needs to merge the contents of this file:
<<<<<<< HEAD
# Add Post
# --- !Ups
CREATE TABLE Post (
id bigint(20) NOT NULL AUTO_INCREMENT,
title varchar(255) NOT NULL,
content text NOT NULL,
postedAt date NOT NULL,
author_id bigint(20) NOT NULL,
FOREIGN KEY (author_id) REFERENCES User(id),
PRIMARY KEY (id)
);
# --- !Downs
DROP TABLE Post;
=======
# Update User
# --- !Ups
ALTER TABLE User ADD age INT;
# --- !Downs
ALTER TABLE User DROP age;
>>>>>>> devB
The merge is really easy to do:
# Add Post and update User
# --- !Ups
ALTER TABLE User ADD age INT;
CREATE TABLE Post (
id bigint(20) NOT NULL AUTO_INCREMENT,
title varchar(255) NOT NULL,
content text NOT NULL,
postedAt date NOT NULL,
author_id bigint(20) NOT NULL,
FOREIGN KEY (author_id) REFERENCES User(id),
PRIMARY KEY (id)
);
# --- !Downs
ALTER TABLE User DROP age;
DROP TABLE Post;
This evolution script represents the new revision 2 of the database, that is different of the previous revision 2 that developer A has already applied.
So Play will detect it and ask developer A to synchronize his database by first reverting the old revision 2 already applied, and by applying the new revision 2 script:
§Inconsistent states
Sometimes you will make a mistake in your evolution scripts, and they will fail. In this case, Play will mark your database schema as being in an inconsistent state and will ask you to manually resolve the problem before continuing.
For example, the Ups script of this evolution has an error:
# Add another column to User
# --- !Ups
ALTER TABLE Userxxx ADD company varchar(255);
# --- !Downs
ALTER TABLE User DROP company;
So trying to apply this evolution will fail, and Play will mark your database schema as inconsistent:
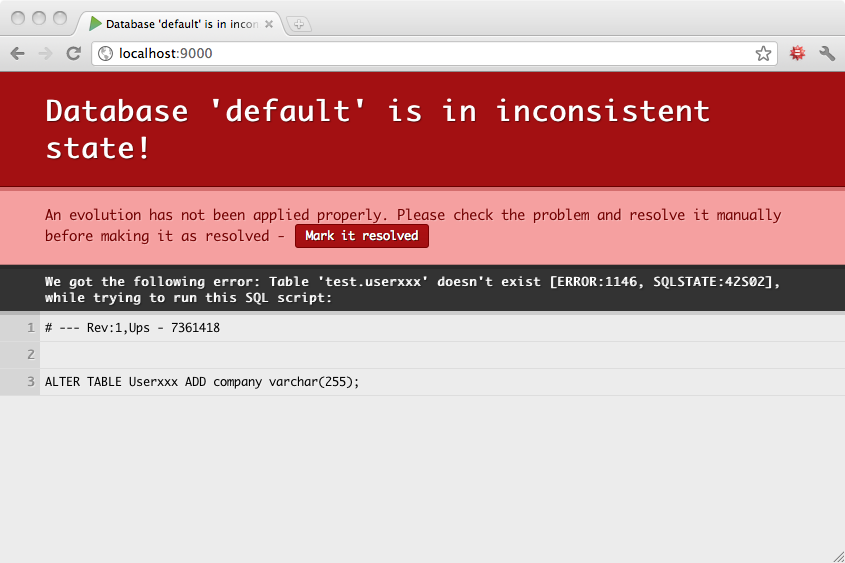
Now before continuing you have to fix this inconsistency. So you run the fixed SQL command:
ALTER TABLE User ADD company varchar(255);
… and then mark this problem as manually resolved by clicking on the button.
But because your evolution script has errors, you probably want to fix it. So you modify the 3.sql script:
# Add another column to User
# --- !Ups
ALTER TABLE User ADD company varchar(255);
# --- !Downs
ALTER TABLE User DROP company;
Play detects this new evolution that replaces the previous 3 one, and will run the appropriate script. Now everything is fixed, and you can continue to work.
In development mode however it is often simpler to simply trash your development database and reapply all evolutions from the beginning.
§Transactional DDL
By default, each statement of each evolution script will be executed immediately. If your database supports Transactional DDL you can set evolutions.autocommit=false in application.conf to change this behaviour, causing all statements to be executed in one transaction only. Now, when an evolution script fails to apply with autocommit disabled, the whole transaction gets rolled back and no changes will be applied at all. So your database stays “clean” and will not become inconsistent. This allows you to easily fix any DDL issues in the evolution scripts without having to modify the database by hand like described above.
§Evolution storage and limitations
Evolutions are stored in your database in a table called play_evolutions. A Text column stores the actual evolution script. Your database probably has a 64kb size limit on a text column. To work around the 64kb limitation you could: manually alter the play_evolutions table structure changing the column type or (preferred) create multiple evolutions scripts less than 64kb in size.
Next: アプリケーションのデプロイ
このドキュメントの翻訳は Play チームによってメンテナンスされているものではありません。 間違いを見つけた場合、このページのソースコードを ここ で確認することができます。 ドキュメントガイドライン を読んで、お気軽にプルリクエストを送ってください。